Authors: Mohammed Salah Al-Radhi, Géza Németh, Branislav Gerazov
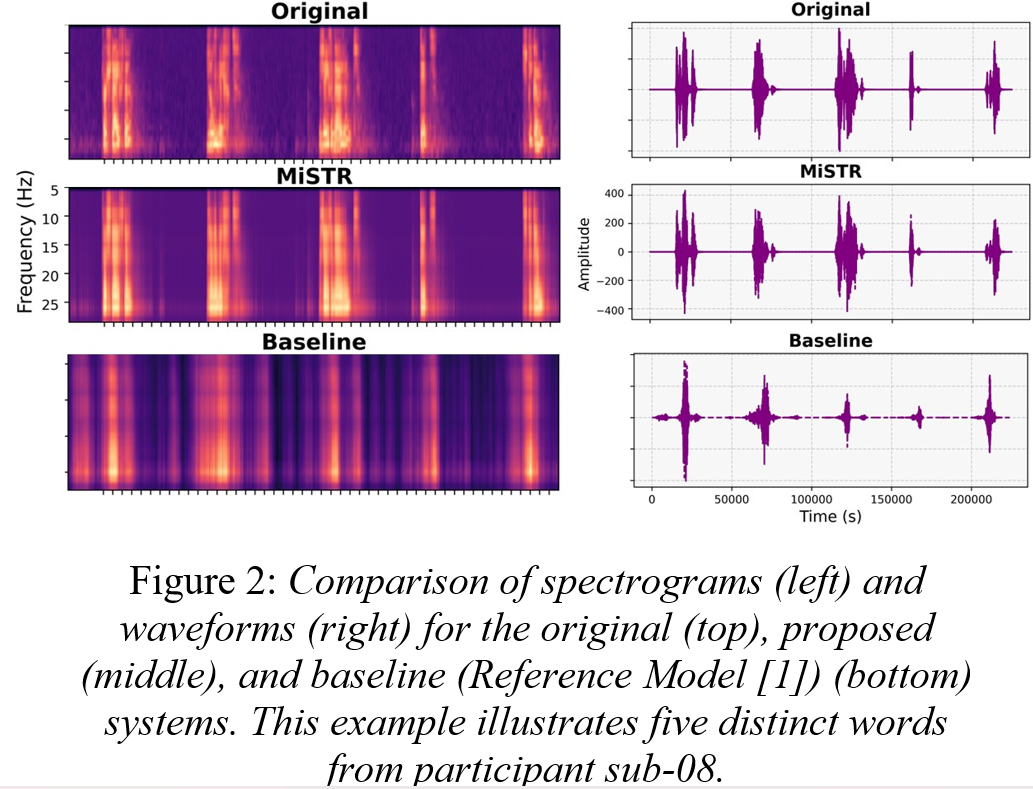
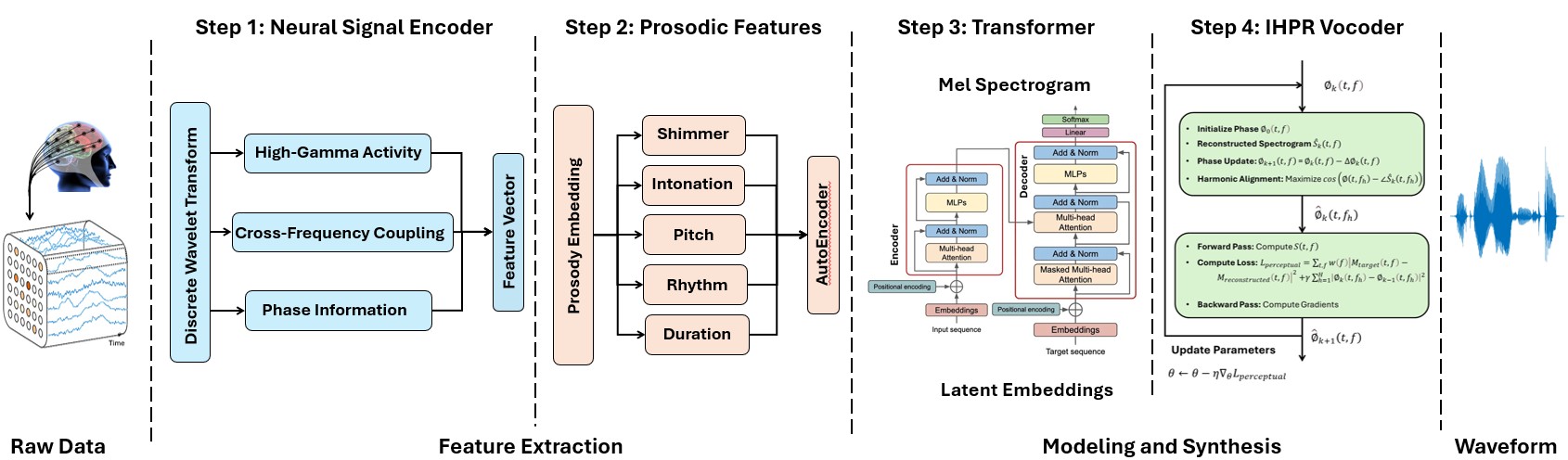
Abstract: Speech synthesis from intracranial EEG (iEEG) signals offers a promising avenue for restoring communication in individuals with severe speech impairments. However, achieving intelligible and natural speech remains challenging due to limitations in feature representation, prosody modeling, and phase reconstruction. We introduce MiSTR, a deep-learning framework that integrates: 1) Wavelet-based feature extraction to capture fine-grained temporal, spectral, and neurophysiological representations of iEEG signals, 2) A Transformer-based decoder for prosody-aware spectrogram prediction, and 3) A neural phase vocoder enforcing harmonic consistency via adaptive spectral correction. Evaluated on a public iEEG dataset, MiSTR achieves state-of-the-art speech intelligibility, with a mean Pearson correlation of 0.91 between reconstructed and original Mel spectrograms, improving over existing neural speech synthesis baselines.
| Natural | Reference Model [1] | MiSTR |
|---|---|---|
| Natural | Reference Model [1] | MiSTR |
|---|---|---|
| Natural | Reference Model [1] | MiSTR |
|---|---|---|
| Natural | Reference Model [1] | MiSTR |
|---|---|---|
Reference Model [1]: M. Verwoert, M.C. Ottenhoff, S. Goulis, et al., "Dataset of Speech Production in Intracranial Electroencephalography," Scientific Data, vol. 9, pp. 1–9, 2022. [DOI]