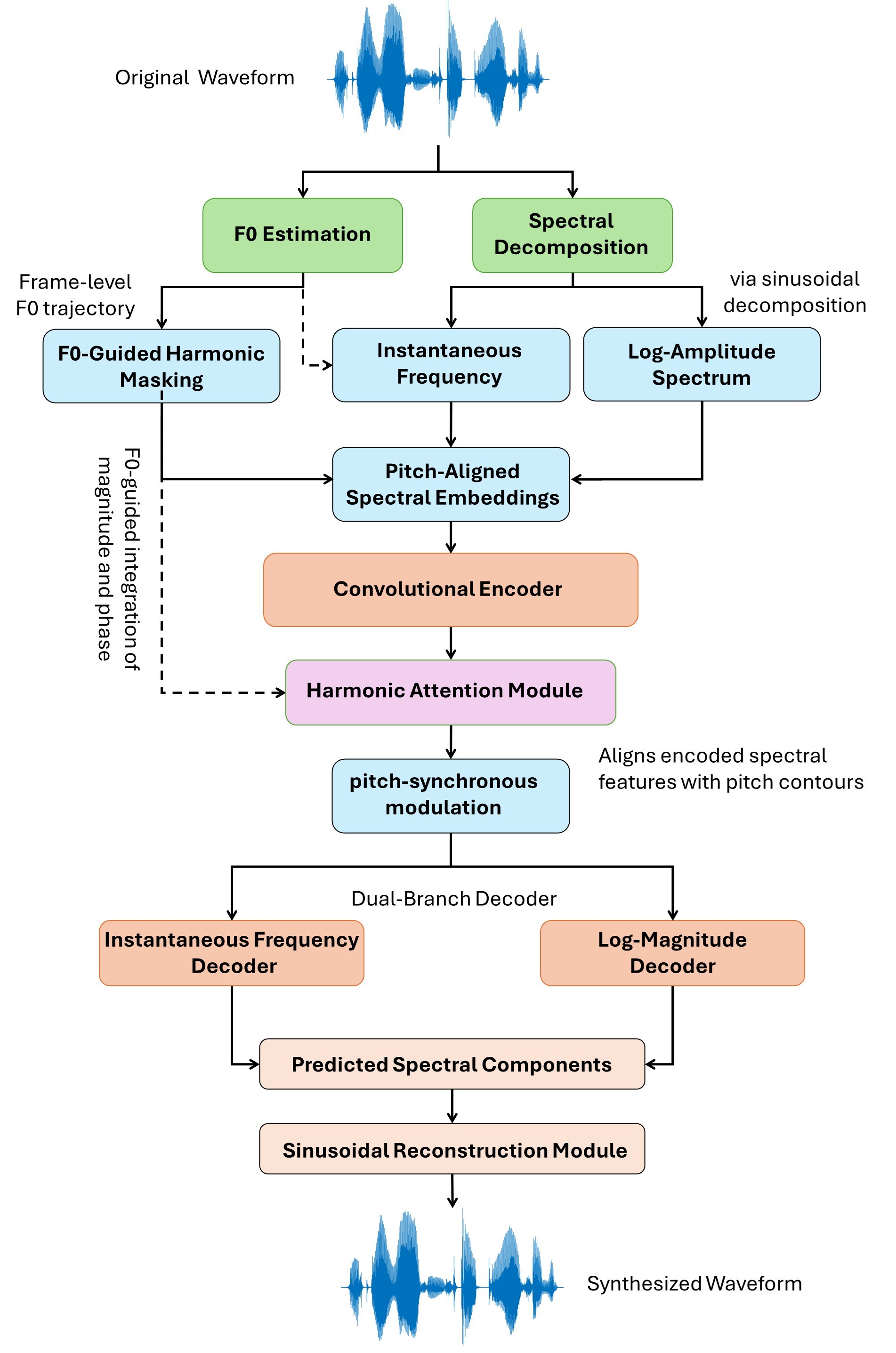
Abstract:
Neural vocoders are central to speech synthesis; despite
their success, most still suffer from limited prosody
modeling and inaccurate phase reconstruction. We propose a
vocoder that introduces prosody-guided harmonic attention
to enhance voiced-segment encoding and directly predicts
complex-spectral components for waveform synthesis via
inverse STFT. Unlike mel-spectrogram–based approaches,
our design jointly models magnitude and phase, ensuring
phase coherence and improved pitch fidelity. To further
align with perceptual quality, we adopt a multi-objective
training strategy that integrates adversarial, spectral, and
phase-aware losses. Experiments on benchmark datasets
demonstrate consistent gains over HiFi-GAN and
AutoVocoder: F0-RMSE reduced by 22%, voiced/unvoiced
error lowered by 18%, and MOS scores improved by 0.15.
These results show that prosody-guided attention combined
with direct complex-spectrum modeling yields more natural,
pitch-accurate, and robust synthetic speech, setting a strong
foundation for expressive neural vocoding.
Samples below are generated using speech from the LJSpeech (female) and VCTK (male/female) datasets.
1) Female Speaker
Sample 1: LJ018-0213
Natural
Anchor
HiFi-GAN
AutoVocoder
Vocos
Proposed
Transcript: which in dramatic interest can compare with the conviction of William Rupel for forgery.
Sample 2: LJ027-0125
Natural
Anchor
HiFi-GAN
AutoVocoder
Vocos
Proposed
Transcript: In the Python we find very tiny rudiments of the hind limbs. Now,
Sample 3: LJ003-0093
Natural
Anchor
HiFi-GAN
AutoVocoder
Vocos
Proposed
Transcript: The oldest only 12 or 13, exposed to all the contaminating influences of the place.
Sample 4: LJ010-0110
Natural
Anchor
HiFi-GAN
AutoVocoder
Vocos
Proposed
Transcript: Several of the other prisoners took the same line as regards Edward's
2) Male Speaker
Sample 1: p226_028
Natural
Anchor
HiFi-GAN
AutoVocoder
Vocos
Proposed
Transcript: Suggestions of the action being a punishment were dismissed.
Sample 2: p226_157
Natural
Anchor
HiFi-GAN
AutoVocoder
Vocos
Proposed
Transcript: Elaine Baxter did not have long to speak on Friday.
Sample 3: p226_299
Natural
Anchor
HiFi-GAN
AutoVocoder
Vocos
Proposed
Transcript: There was no hint of scandal.
Sample 4: p226_068
Natural
Anchor
HiFi-GAN
AutoVocoder
Vocos
Proposed
Transcript: Scotland has great assets.
Analysis Figures
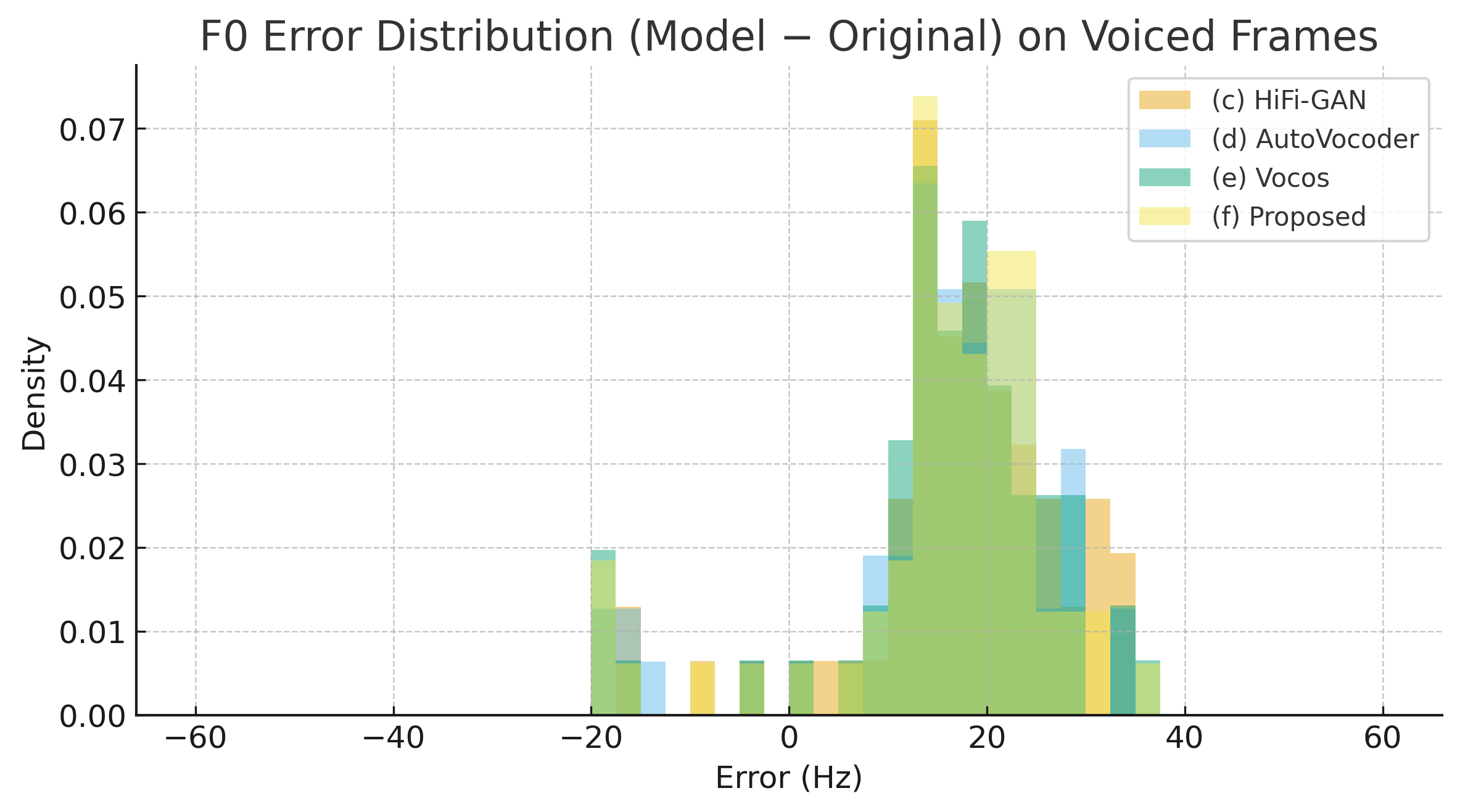
Figure 1.F0 error distribution between model outputs and the original signal on voiced frames.
The Proposed model achieves the tightest clustering near zero error, indicating superior
pitch tracking compared to HiFi-GAN, AutoVocoder, and Vocos.
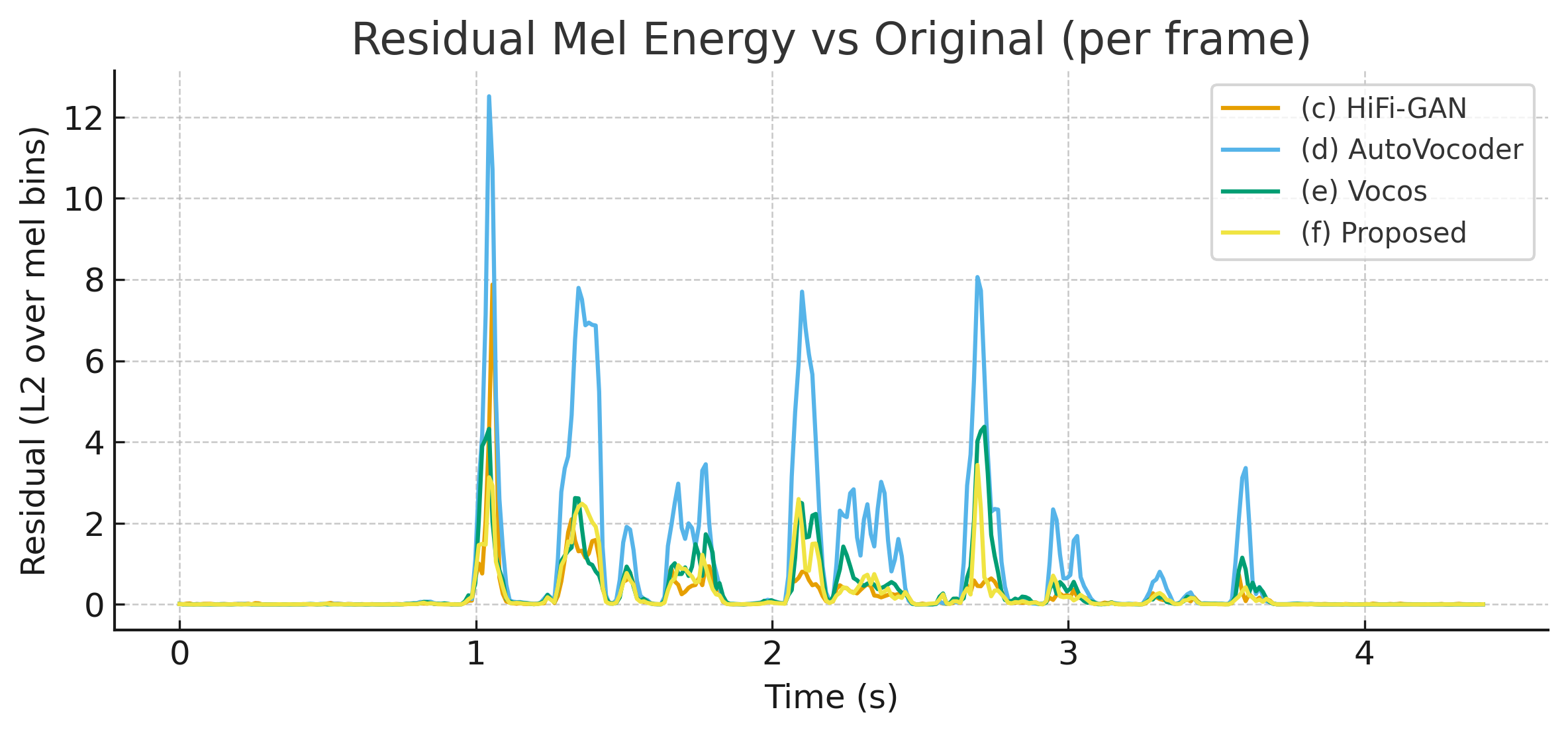
Figure 2.Residual mel energy (L2 difference) over time compared to the original.
The Proposed model and HiFi-GAN maintain consistently low residuals, while
AutoVocoder exhibits large error spikes and Vocos shows higher variability.
Figure 3.Mel-spectrograms with F0 overlays. HiFi-GAN produces smoother but weaker harmonics,
AutoVocoder retains harmonics with noticeable smearing, and Vocos yields fuzzy, unstable
structures. The Proposed method best preserves harmonic sharpness and F0 alignment, closely
resembling the original.Figure 4.Zoomed-in Mel+F0 segment. The Proposed model maintains sharp, well-aligned harmonics,
while AutoVocoder produces smeared bands, HiFi-GAN shows smoother but drifting pitch,
and Vocos displays unstable harmonics.